![]()
![]()
![]()
![]()
![]()
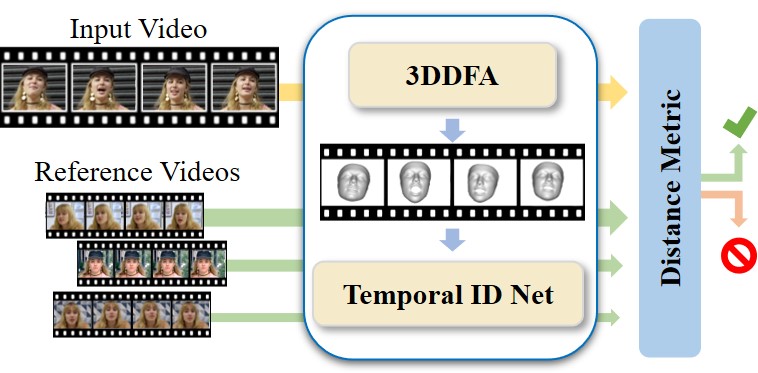
A major challenge in DeepFake forgery detection is that state-of-the-art algorithms are mostly trained to detect a specific fake method. As a result, these approaches show poor generalization across different types of facial manipulations, e.g., from face swapping to facial reenactment. To this end, we introduce ID-Reveal, a new approach that learns temporal facial features, specific of how a person moves while talking, by means of metric learning coupled with an adversarial training strategy. The advantage is that we do not need any training data of fakes, but only train on real videos. Moreover, we utilize high-level semantic features, which enables robustness to widespread and disruptive forms of post-processing. We perform a thorough experimental analysis on several publicly available benchmarks. Compared to state of the art, our method improves generalization and is more robust to low-quality videos, that are usually spread over social networks. In particular, we obtain an average improvement of more than 15% in terms of accuracy for facial reenactment on high compressed videos.
Bibtex
@inproceedings{cozzolino2021reveal,
title={Id-Reveal: Identity-aware deepfake video detection},
author={Cozzolino, Davide and R{\"o}ssler, Andreas and Thies, Justus and Nie{\ss}ner, Matthias and Verdoliva, Luisa},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={15108--15117},
year={2021}
}
Acknowledgments
We gratefully acknowledge the support of this research by a TUM-IAS Hans Fischer Senior Fellowship, a TUM-IAS Rudolf Moßbauer Fellowship and a Google Faculty Research Award. In addition, this material is based on research sponsored by the Defense Advanced Research Projects Agency (DARPA) and the Air Force Research Laboratory (AFRL) under agreement number FA8750-20-2-1004. he U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of DARPA and AFRL or the U.S. Government.
This work is also supported by the PREMIER project, funded by the Italian Ministry of Education, University, and Research within the PRIN 2017 program.